NVIDIA Hopper Architecture - the engine for the world’s AI infrastructure
Graphics processing units (GPU) were initially developed to accelerate memory-intensive calculations required in graphical rendering. While they are still used for this purpose, their capabilities work well also for many scientific computing jobs. GPUs have become an essential part of a modern artificial intelligence infrastructure. An example is the presence of 37,000 accelerators in the world’s most powerful supercomputer. The fundamental idea is that GPU works in tandem with a CPU to improve the throughput of data and the number of concurrent calculations within the application. This approach is often called “heterogeneous” or “hybrid” computing.
A leader among dedicated graphics card vendors is NVIDIA, with about 80% of the market share. Currently, we are waiting for the next generation of high-performance accelerators for servers – H100, announced in March 2022 at NVIDIA’s annual spring GTC event. According to the newest information from NVIDIA, the accelerator is in full production and shipping of products will begin soon.
NVIDIA has a habit of naming the next generations of GPUs after outstanding scientists (e.g. Ampere, Volta, Pascal, Maxwell, Keppler). The codename of the upcoming generation is Hopper to honour Grace Hopper (1906-1992), an outstanding American programmer and mathematician. She was a programmer of Harvard Mark I, one of the first computers, and helped develop Mark II and Mark III. Moreover, she contributed to creating one of the oldest programming languages – COBOL (Common Business Oriented Language).
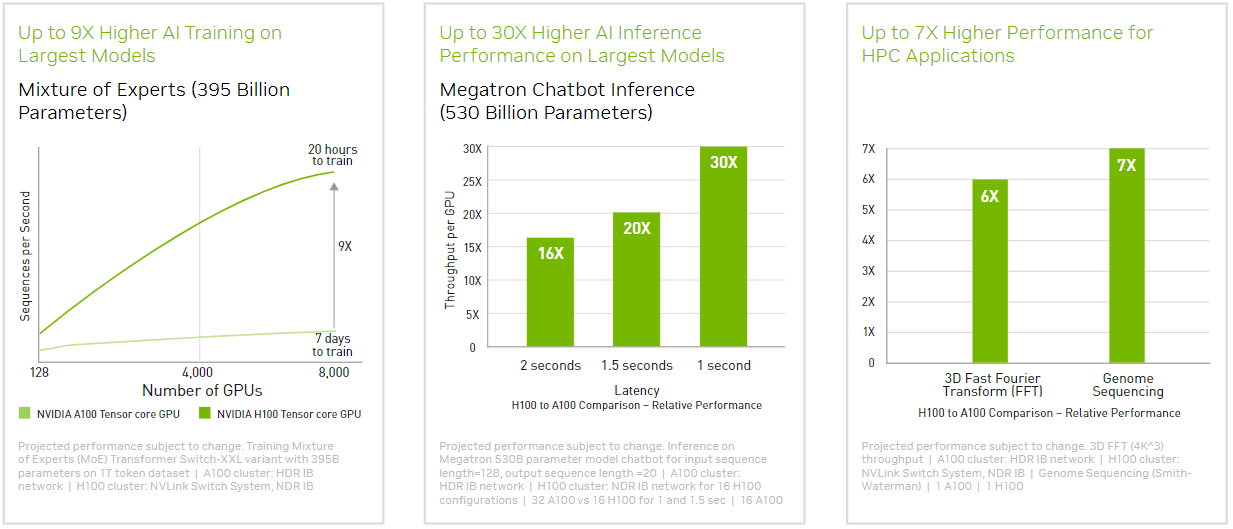
H100 is the follow-up to NVIDIA’s very successful A100 accelerator. It uses breakthrough innovations of the NVIDIA Hopper architecture and achieves up to 30x better performance (see Figure 1) than the previous generation. The newest accelerator is based on the advanced TSMC 4N process and consists of 80 billion transistors. At the same time, NVIDIA becomes the first accelerator vendor to use the latest-generation version of the high bandwidth memory. The H100 accelerator implements HBM3 memory and significantly improves memory bandwidth over the previous generation, offering 3TB/second. It also pushes the envelope in terms of power consumption, with a maximum TDP of 700 Watts.
Table 1 NVIDIA H100 compared to accelerators of previous generations
Figure 1 Performance comparison of NVIDIA H100 and A100 accelerators [2]
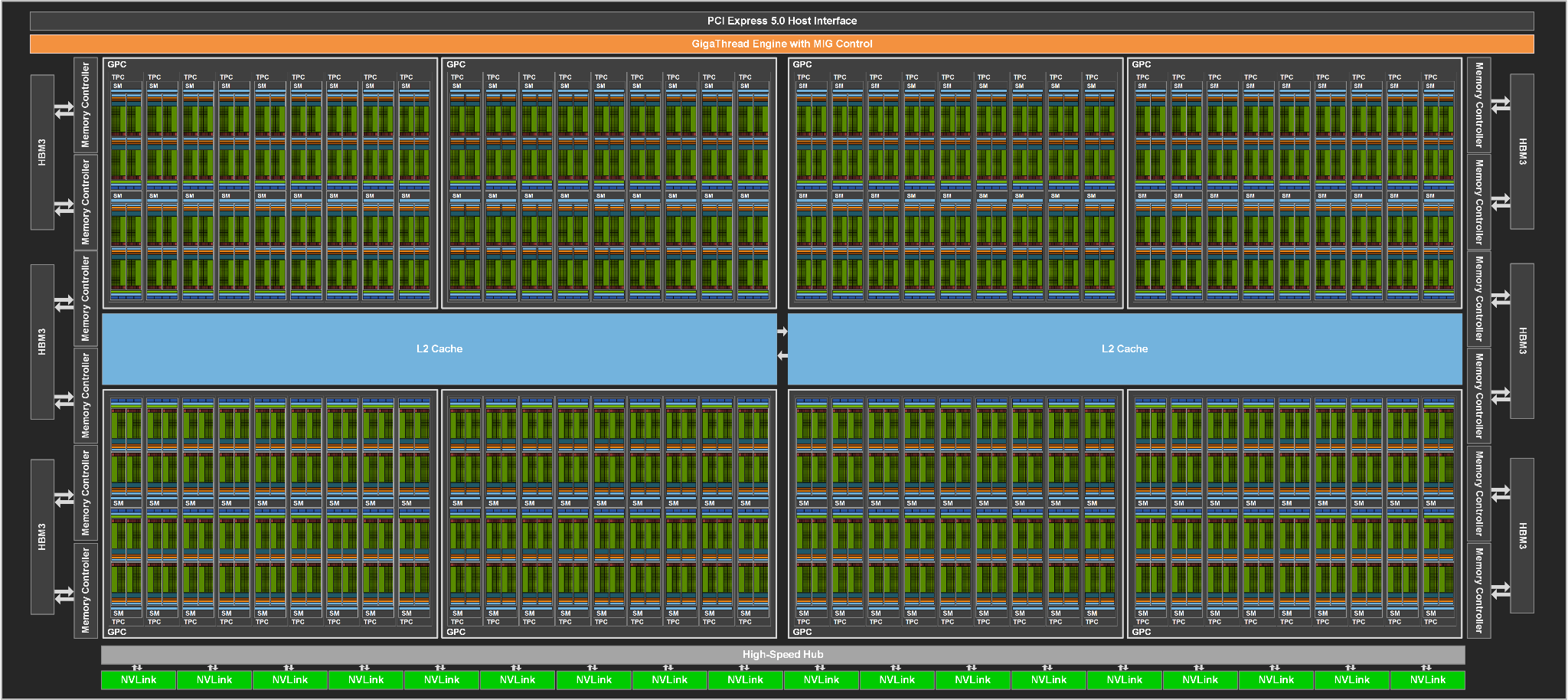
Figure 2 Architecture of the NVIDIA H100 accelerator
The following sentence shows the importance and possibilities of the new accelerator in the AI area. To quote NVIDIA, “twenty H100 GPUs can sustain the equivalent of the entire world’s internet traffic, making it possible for customers to deliver advanced recommender systems and large language models running inference on data in real-time”.
MARVEL project is also looking forward to this new generation of high-performance GPUs since our partner PSNC is planning to build a new computing system based on Hopper architecture next year. It will support MARVEL to take full advantage of the AI-based algorithms for audio-visual analytics of smart cities.
This project has received funding from the European Union’s Horizon 2020 Research and Innovation program under grant agreement No 957337. The website reflects only the view of the author(s) and the Commission is not responsible for any use that may be made of the information it contains.
We may use cookies to ensure that we give you the best experience on this website. Do you accept cookies?