Enhancing the Performance of Lightweight Networks by Image Captioning and Image Generation

Deep neural networks consume a lot of resources. In many applications such as those related to smart cities, computational resources are very limited. In such cases, lightweight neural networks can be used to decrease the computational burden. However, lightweight neural networks are usually not as accurate as their heavyweight counterparts when trained following standard practices. Thus, there is a great amount of research on how to make lightweight neural networks more accurate. One of these research directions is to artificially boost the size of existing datasets used for training neural networks. This approach is called training with data augmentation. This has become a common practice nowadays, and simple augmentations, for instance, by slight image modifications by means of rotation, flip, or adjusting brightness, have been extensively used for training. However, while all these simple data augmentations provide more variations in the data to be considered in training, they do not provide radically different samples which can really enrich the information included in the dataset.
Researchers at Aarhus University proposed a new approach called PromptMix to increase the accuracy of lightweight networks. In their method, they take advantage of the recently proposed image generators called Latent Diffusion Models (LDMs), which can be used to create realistic images from given text. First, images in existing datasets are given to an image captioning deep neural network to obtain text descriptions for each image. These text descriptions are then given to image generators to generate artificial images that resemble the original ones. Finally, these are labeled using heavyweight neural networks and mixed with real images during the training of lightweight networks.
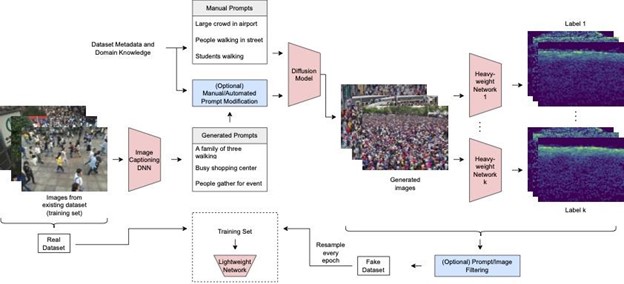
It was shown that using PromptMix for training lightweight networks can significantly improve their performance on two tasks, namely, crowd counting, where the goal is to count the total number of people present in a given image; and monocular depth estimation, which aims to provide the depth (distance to the camera) for each pixel of a given image. PromptMix has the potential to be useful in various other computer vision tasks as well. Check out the paper describing the methodology here [1].
Reference
[1] A. Bakhtiarnia, Q. Zhang and A. Iosifidis, “PromptMix: Text-to-image diffusion models enhance the performance of lightweight networks”, arXiv:2301.12914, 2023
Blog signed by: AU team
Menu
- Home
- About
- Experimentation
- Knowledge Hub
- ContactResults
- News & Events
- Contact
Funding

This project has received funding from the European Union’s Horizon 2020 Research and Innovation program under grant agreement No 957337. The website reflects only the view of the author(s) and the Commission is not responsible for any use that may be made of the information it contains.