Apache NiFi ecosystem: Connecting the dots of the computing continuum
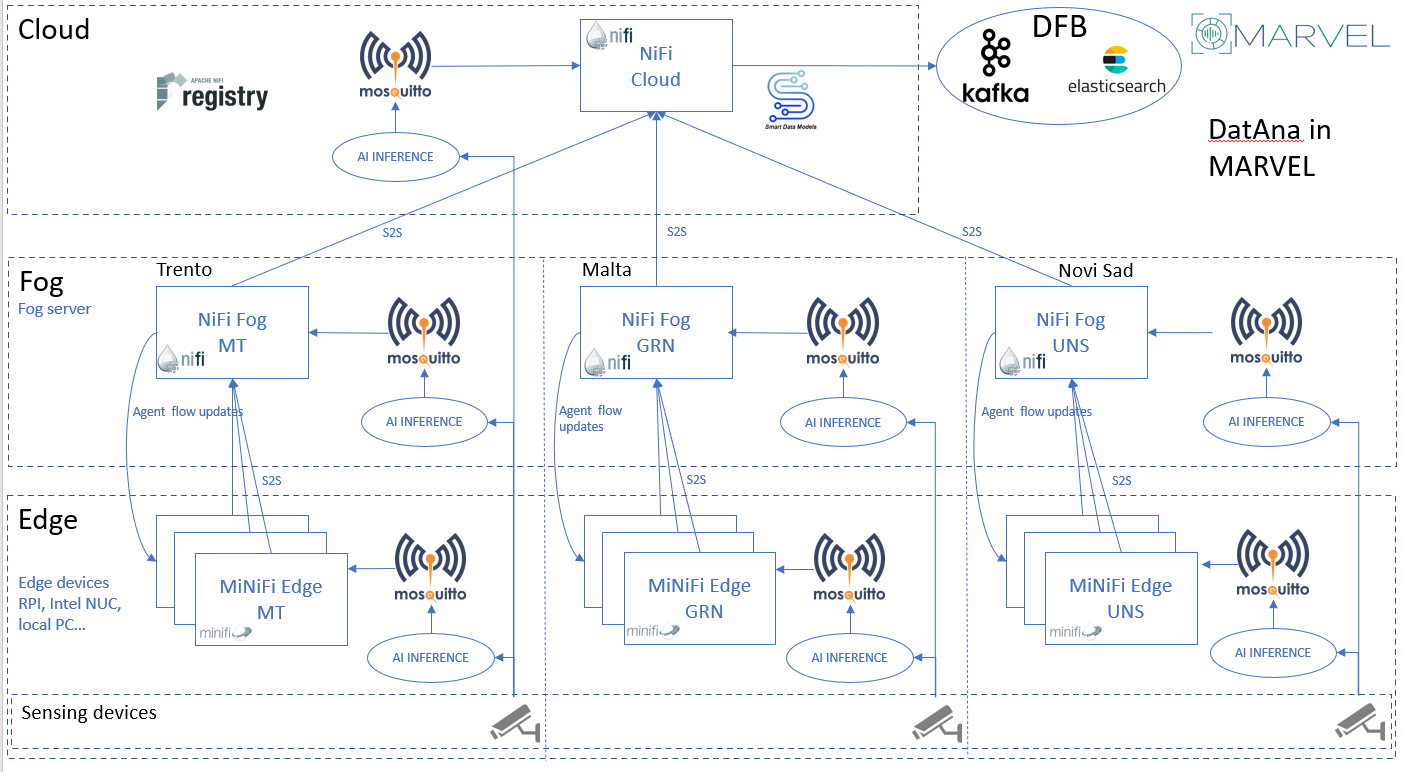
The trend towards more powerful devices and gateways at the edge is bringing huge possibilities to analyse data closer to where it is produced. This trend provides many advantages, among them minimizing the data transfer, which in turn increases security and reduces privacy concerns. However, to achieve this it is necessary to have the correct hardware at the edge, typically including GPUs to run compressed versions of inference algorithms, as well as systems for data management to control the flow of data to upper layers, such as fog servers or the cloud. These data management platforms have the role of connecting the dots among the different layers of the computing continuum, providing an abstraction layer that helps other systems to plug their data and analyse it where it is required.
One such data management platform in MARVEL is DatAna. DatAna is using behind the scenes a set of the Apache NiFi ecosystem of tools, such as NiFi, MiNiFi, and NiFi Registry. It relies on the definition of data processing flows using the NiFi user interface to deploy ETL data management pipelines at the right layer. NiFi provides an extensible and ample set of off-the-shelf data processors, as well as the possibility of connecting different layers using the NiFi Site-to-Site (S2S) protocol. Besides collecting, manipulating and enriching the results in each of the layers, S2S allows the communication among nodes of the computing continuum, both for batch and real-time streaming data.
The main role of DatAna in MARVEL is in the streaming and batch data inference pipeline. In particular, the streaming data inference is achieved in real-time near where data is produced, or in the layer of choice, where inference algorithms process the incoming data from cameras or mics. Messages with the results of the inference algorithms are published in MQTT brokers. DatAna subscribes to the brokers transforming and aligning the results to the expected MARVEL data models, based on the Smart Data Models initiative sponsored by FIWARE, TM Forum, IUDX, and OASC. Eventually, the results are communicated in a streaming fashion to an Apache Kafka Broker (belonging to the Data Fusion Bus component) for further processing and storage in the cloud. The whole process can be achieved in near-real time, enabling rapid decision-making based on the data and the visualizations provided by the MARVEL framework.
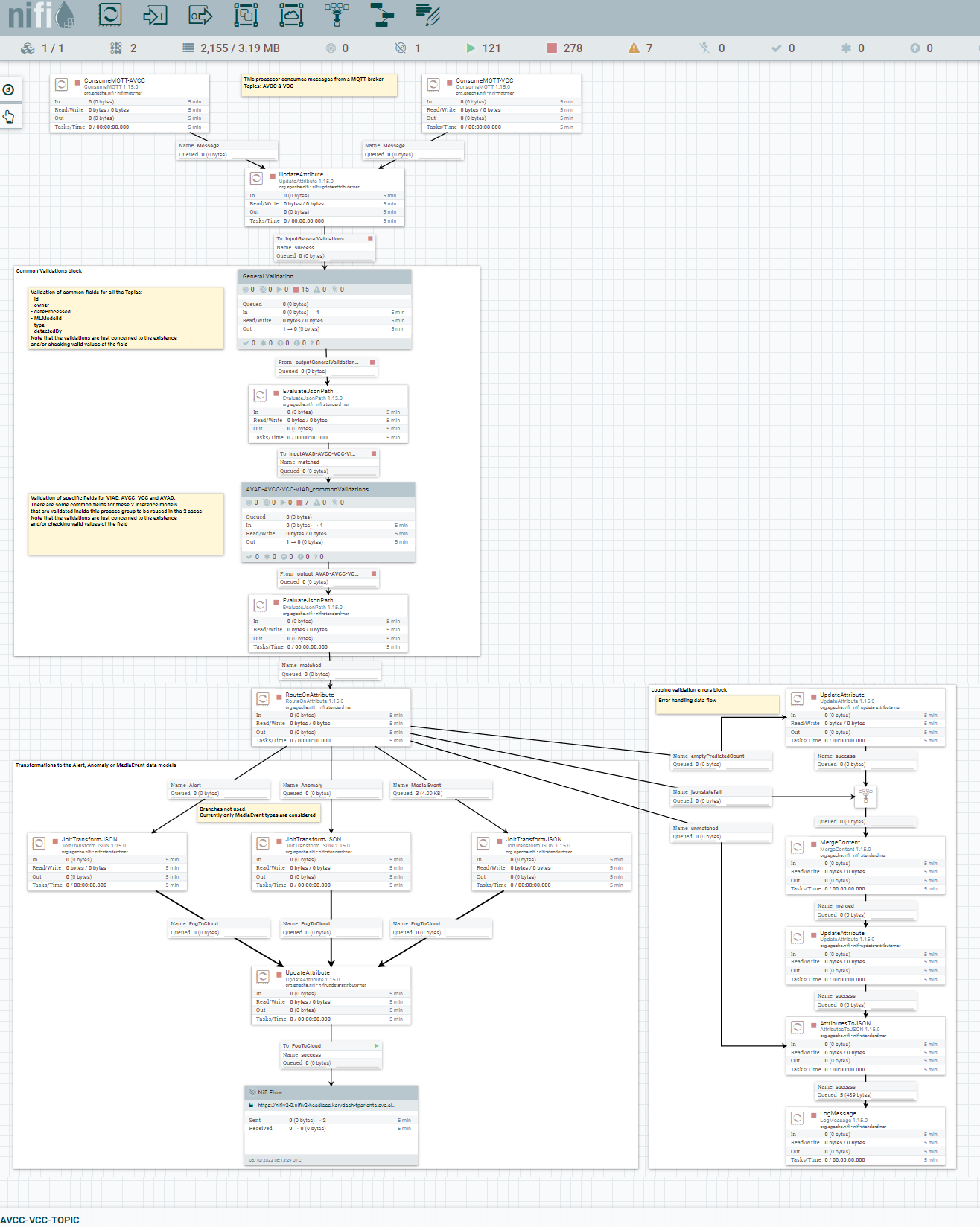
The low footprint of Apache MiNiFi gives the possibility of deploying it in elements at the edge such as Raspberry Pis or other devices, which makes it ideal to process data at the edge once the inference algorithms have done their magic over the AV data streams and communicate the numerical results to upper layers or even issue-specific alerts after anomalies or events are detected. Other Apache NiFi instances at the fog and cloud layers, connected securely via authentication mechanisms, process the results, as well as proceed to analyse or fetch new data for ulterior enrichment. From the application developer’s perspective, NiFi offers an easy-to-use graphical user interface environment for defining complex data flows, which reduces the learning curve and implies no or very low coding.
NiFi provides administrators with tons of possibilities for configuring and scaling NiFi clusters, both horizontally and vertically. This focus on scalability enables high throughput and low latency data processing flows.
Connecting the dots of the computing continuum was never easier, unless, as usual, the devil dwells on the details. But this is a different story.
Blog signed by: Tomás Pariente Lobo of the ATOS team
Menu
- Home
- About
- Experimentation
- Knowledge Hub
- ContactResults
- News & Events
- Contact
Funding

This project has received funding from the European Union’s Horizon 2020 Research and Innovation program under grant agreement No 957337. The website reflects only the view of the author(s) and the Commission is not responsible for any use that may be made of the information it contains.